FAST 23-OSML 阅读笔记
Intelligent Resource Scheduling for Co-located Latency-critical Services: A Multi-Model Collaborative Learning Approach
作者:Lei Liu, Xinglei Dou, Yuetao Chen
会议:FAST
年份:2023
为了性价比的考虑,多种延迟敏感负载共同使用服务器。资源调度成为保证QoS的核心。但是,随着服务器资源的增多,资源调度越来越复杂,传统的调度器难以迅速高效地提供最优的策略。而且,” 资源峭壁”的存在也使得QoS存在抖动。为了解决这一问题,作者提出了OSML——基于机器学习的智能调度器。OSML主要学习硬件hint(如IPC、cache miss率、内存足迹等)、调度解决方案和QoS需求之间的关系,能预测QoS的变化、指导调度并且从违反QoS要求的情况下恢复回来。通过实验验证,OSML支持更高的负载、用更低的调度小号满足QoS需求,且和之前的调度器相比,缩短了收敛的时间。
开源网址(将在2023年八月公开)
https://github.com/Sys-Inventor-Lab/AI4System-OSML
背景
云应用由许多延迟敏感(Latency Critical, aka LC)服务组成,例如KV存储、数据库查询等,如下表。LC服务需要满足严格的QoS要求。
一方面,为了提高性价比,云服务提供商往往会在一个服务器上部署尽量多的应用。然而,这些应用,或者说组成它们的各类服务,在不同时间段,和各种层级的资源的交互模式多种多样,如CPU核、缓存、内存I/O带宽、内存bank等。同时,随着CPU核数增多,线程间对LLC(last-level cache)和内存带宽的竞争愈加激烈。甚至资源之间也存在交互。另一方面,随着硬件技术的发展,可调度的资源相比十年有了巨大提升,如Table 2,调度的“域”变大。在这一场景下对LC服务的资源调度非常复杂且耗时,这一现状对以QoS为导向的资源调度器的设计提出了不小的挑战。
现有工作
有些工作使用聚类算法把LLC和内存带宽分配给核,其中每个核调度单个线程。这种办法不适合云应用场景,因为这个场景下一般同时运行多个线程且每个线程都有严格的QoS要求。
其他工作要么使用启发式的思路——即某个时刻减少/增加某类资源,随后观察性能的变化,要么以相对直接的方式借助机器学习算法(如贝叶斯优化)进行资源调度。研究表明,用这些办法调度5个一起运行的LC服务,并且使它们都满足QoS需求需要花费20s(也就是说需要花20s来决策?)。
现有工作还可以在调度收敛时间、智能性和规定时间内完成复杂的交互式资源调度上有提升空间。以及还有一个重要的问题:它们能在多个LC服务同时部署在现代服务器上时,提供最优的资源调度策略吗?
动机
为了回答上述问题,作者分析了LC服务(如Table 1)的特征。实验环境如下Table 2左列所示。
资源峭壁(RCliff)与最佳分配区域(OAA)
分析表明,LC服务对关键资源非常敏感,即使只少分配一点,也会造成巨大的QoS下滑。作者把这一现象称为“资源峭壁(Resource Cliff, aka RCliff)“。
这里所说的“关键资源”是如CPU核这类计算资源和如LLC ways这类存储资源。
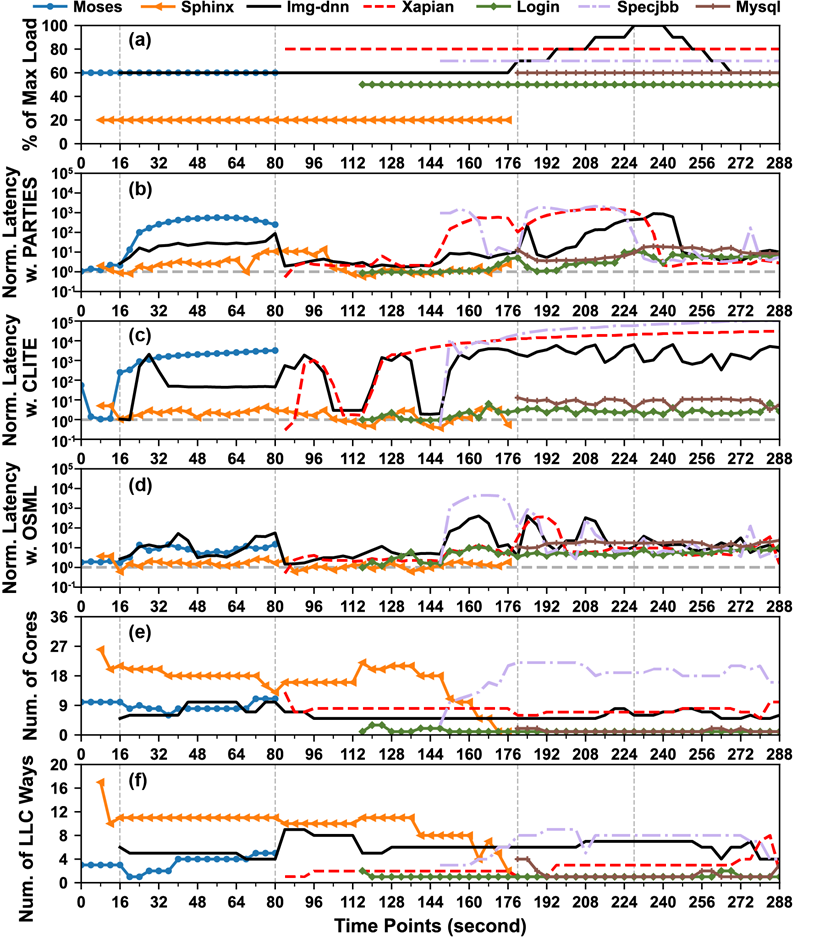
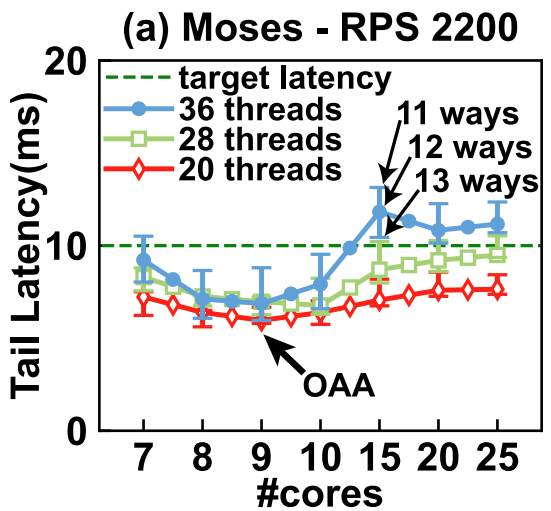
作者测试了Table 1中列出的benchmark,每次实验均使用36个线程,以其中的Moses为代表,实验结果如下图:(方格内的数字表示响应延迟)
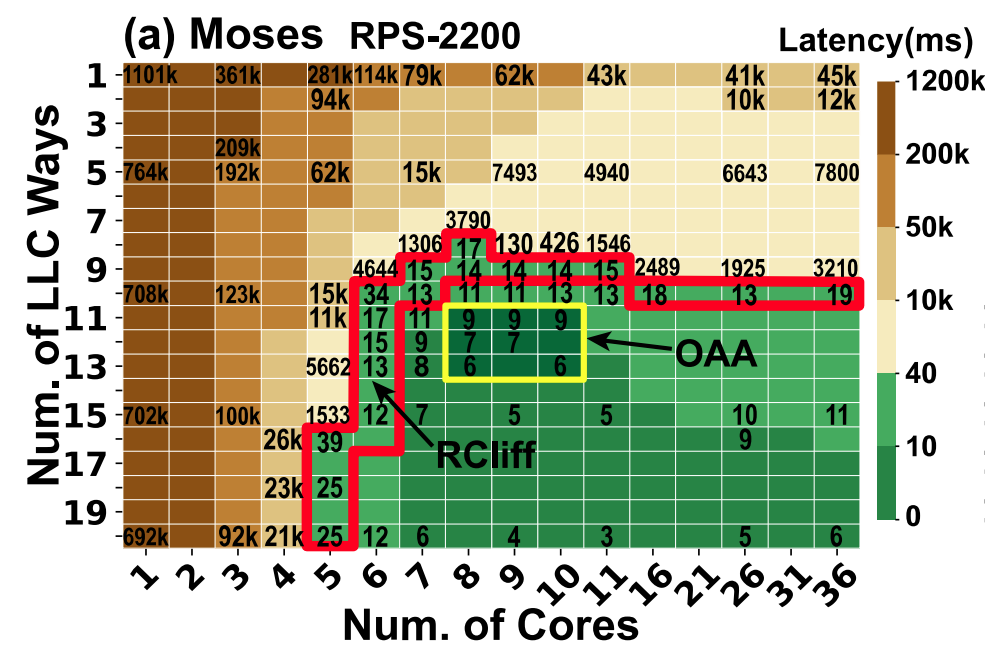
当Core数目为6时,即使只减少1个LLC Way(从10减为9),响应延迟从34ms急速增长到4644ms。LLC Way固定,减少Core数也有类似的现象。作者把存在这一现象的区域用红框框起来了,如上图所示。
- 造成Cache Cliff的原因是局部性。
- 造成Core Cliff的原因在于排队理论:当请求到达速率超过核数以及核的处理速率时,延迟会急速增长。
调度器应该避免分配分配的资源落在资源峭壁边缘。
因此,作者划出了最佳分配区域(Optimal Allocation Area, aka OAA),如上图黄框内区域,即满足QoS要求,又不至于分配过多资源。
不同的benchmark下能划出不同的RCliff区和OAA。
由于在实践中常常多个线程并发执行,所以引出下一个问题,OAA会随着线程数变化而变化吗?
OAA与线程数的关系
依然以Moses为例,如下图,不论线程数是20、28还是36,最佳的core都在8~10之间,说明OAA对线程数的变化不敏感。
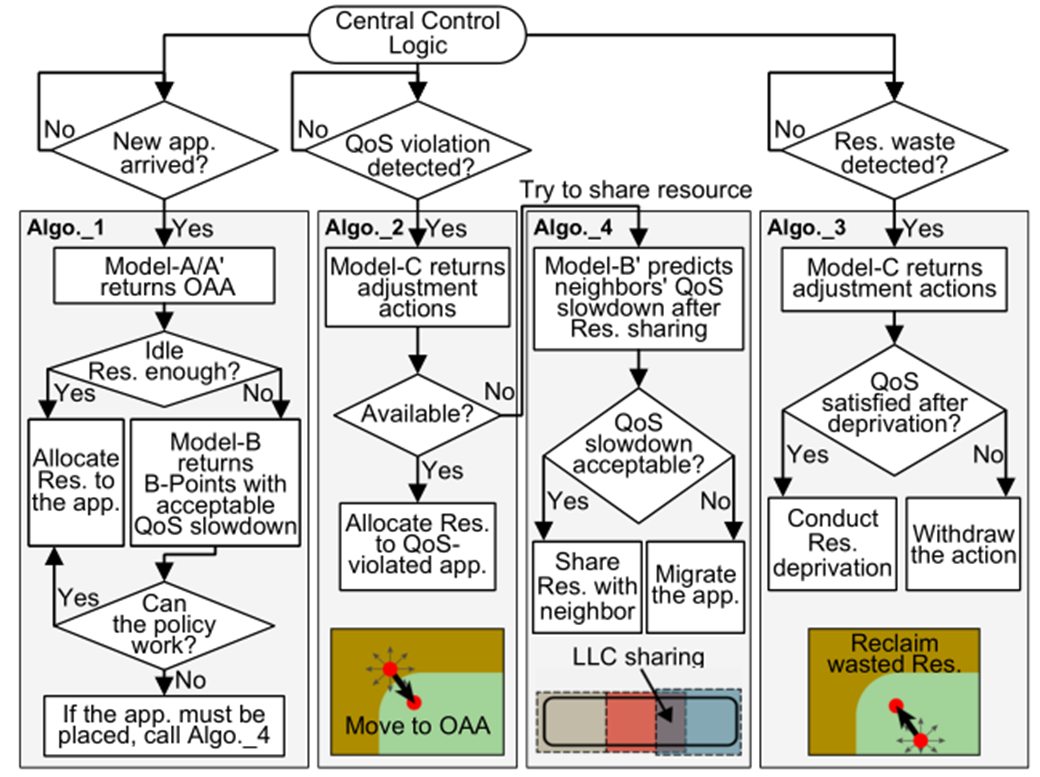
现有的调度器可能遇到的问题
- 容易在RCliff周围徘徊
现有的启发式调度器根据观察到的性能变化增多/减少分配的资源,一方面,若给某应用分配的资源在RCliff之前(即图1中的黄色区域),由于它们对OAA没有概念,所以只能一步步细粒度地调整分配的资源;另一方面,若给某应用分配的资源在RCliff区内,则一点点资源的减少都会造成性能突然下降。
- 没法同时调度多种交互资源(如core、LCC way)以迅速到达OAA
启发式算法往往只调度一种资源。当需要调度多种资源时,往往需要花费较长时间才能达到OAA。
- 没法准确预测整体的QoS
要么违背QoS要求,要么分配过多预留资源。
总之,新的调度器的开发迫在眉睫。使用机器学习可以以较低的开销在复杂的情况下完全调度。
OSML:利用机器学习进行调度
作者把调度的过程分为三个routine,并分别使用不同的机器学习模型:
1)Model A和Model B是静态的机器学习模型,分别负责预测OAA/RCliff和在多LC服务同时进行时,平衡QoS和所分配的资源;
2)Model C是强化学习模型,负责动态指导资源分配。
Overview
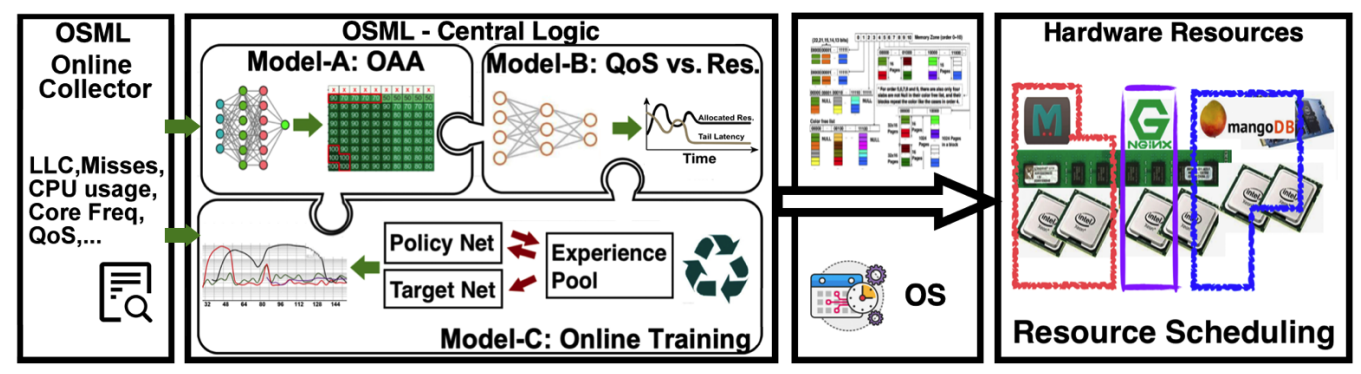
Central Logic
实验
- 评测指标
QoS:99th延迟
EMU:即Effiective Machine Utilization,代表所有共同运行的LC服务的最大负载
- 对比的方案
- PARTIES:一个启发式调度策略
- CLITE:一个基于贝叶斯优化的调度策略
- Unmanaged Allocation:不调度,代表下限
- ORACLE:离线学习了大量数据并且找到了最好的方案,代表上限
实验结果
- 由于Model A提供的出发点更接近OAA,所以OSML能用更短的收敛时间实现同样的EMU
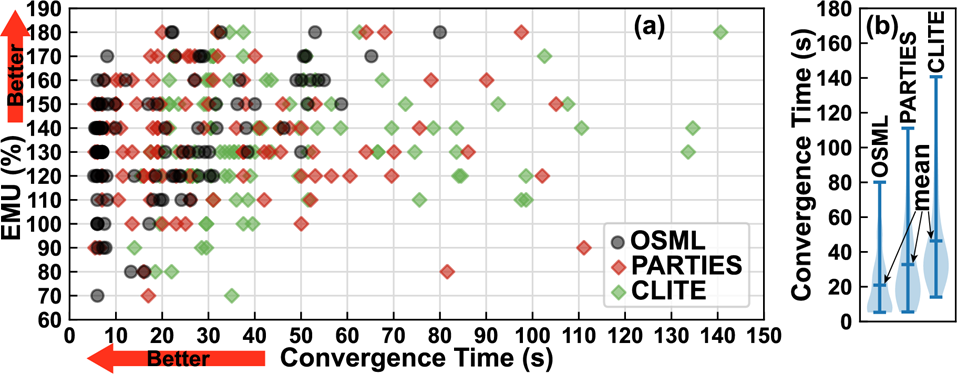
- 同样的Load,OSML可以使用更少的资源使它们达到QoS要求
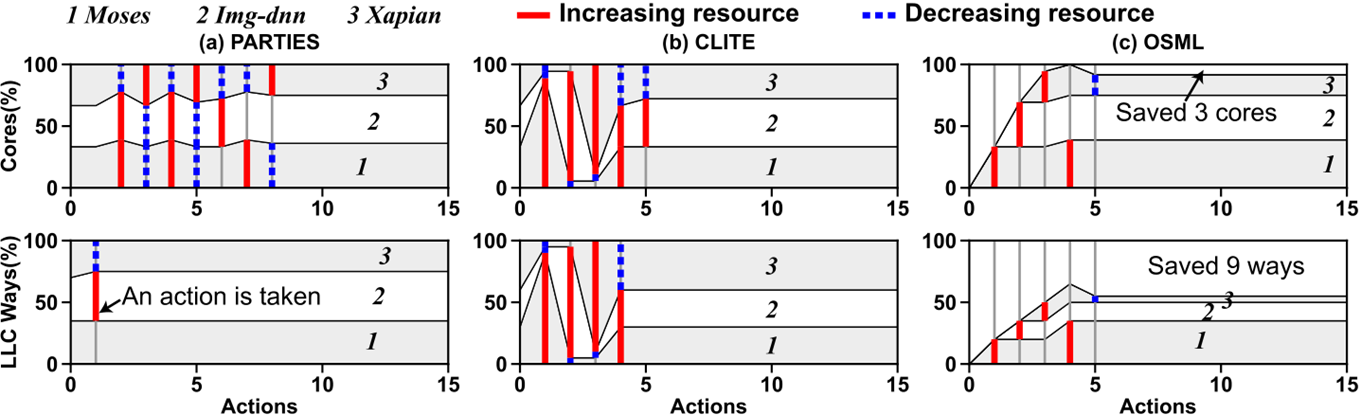
- 由于OSML支持资源共享,所以能支持更多load
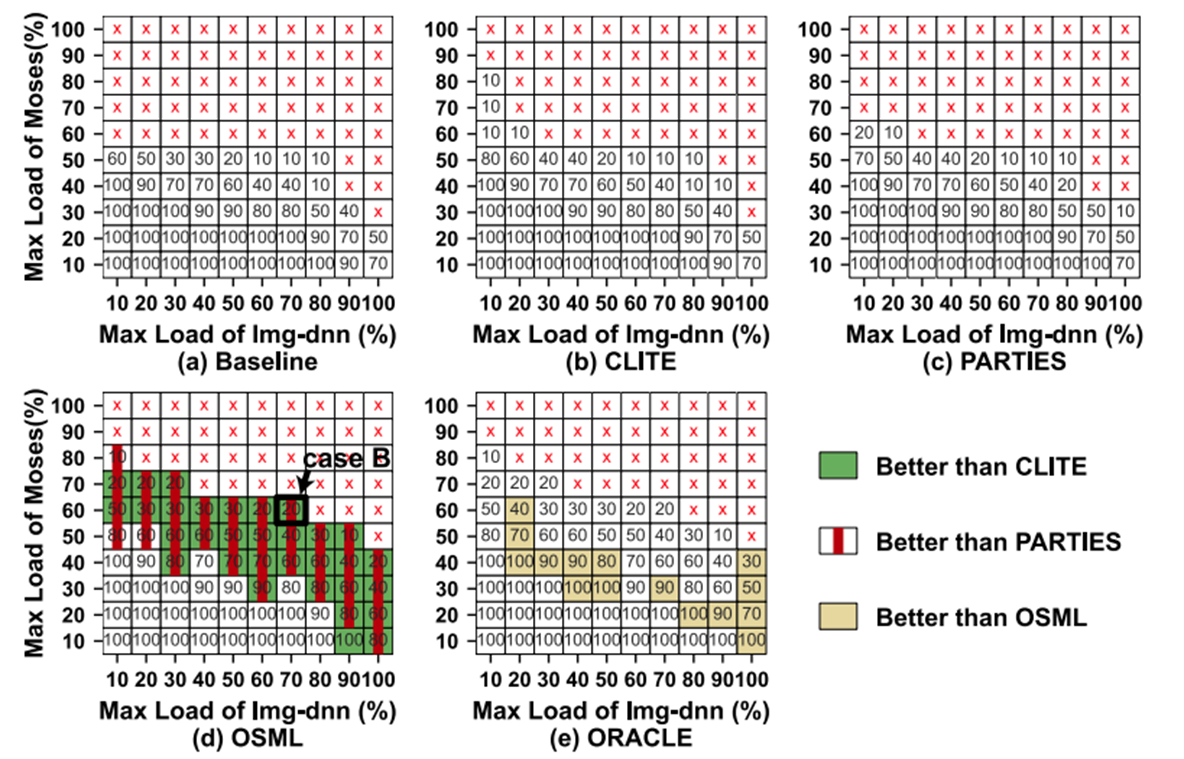
- 由于Model C的动态调整,在新服务到来/旧load发生变化时,OSML能更快调整