
ChCore-lab-v2-ECNUver: LAB 2
实验2:内存管理
本实验主要目的在于让同学们熟悉计算机进行地址翻译的过程,并且了解计算机启动过程中,如何对内存初始化,以及启动完成后对内存和页表的管理。
包括三个部分:内核启动页表、物理内存管理和页表管理。
注:为了帮助同学们了解这些知识,本节会出现少量“小思考”,不会算入实验报告评分。
课堂回顾:地址翻译机制与多级页表
本部分为地址翻译的介绍,若对这一部分有充分了解的同学可以放心跳过~(但不要跳过思考题)
地址翻译的机制
内存的访问粒度是Byte(即每次最少读/写一个Byte),每个Byte有一个“编号”,这个“编号”就是地址。地址空间 就是可以访问的地址的集合。
C语言中的指针变量存储的就是数据的地址,我们可以通过%p在printf函数中输出它,例如下面的代码:
1 |
|
输出结果(运行于x86-64平台、Linux操作系统)为:
1 | misao@misao-virtual-machine:~$ ./test |
这个地址是 虚拟地址 ,即应用“看到”,并且使用的地址。数据(如上面的代码中的n)在内存中实际存储的位置是 物理地址 ,也即访问内存实际用的地址。
这就引出了两个值得思考的问题:
问题一:既然需要使用物理地址访问内存,操作系统为什么不直接让应用使用物理地址呢?
如果操作系统允许应用直接使用物理地址,那么会有两个棘手的问题:第一,难以保证不同应用之间的内存隔离。例如,应用A给变量n赋值10,另一应用B可能故意或者不小心把n改成其他值,进而导致A的运行出错;第二,难以保证一个应用的地址空间连续且统一,当一台机器同时运行多个应用时,它们共享同一块内存,应用难以判断自己可用的空间有多少,此时内存的布局会变得非常复杂。
这两个难题的原因就是没有一个”领导“协调多个应用对同一个内存的使用,因此,需要操作系统对内存进行统一管理。
为了实现这一点,需要对物理内存 虚拟化 ,即令每个应用都认为自己可以使用整块连续的内存,所以说应用使用的地址是虚拟地址,在实际访问时再根据操作系统指定的地址翻译规则进行地址翻译,把虚拟地址翻译为物理地址。
问题二:虚拟地址到物理地址的转化(翻译)是如何执行的?
虚拟地址的转化(翻译)是由CPU(硬件)配合操作系统(软件)完成的。一方面,CPU根据地址翻译规则,把虚拟地址转化为物理地址,然后通过总线进行内存读写操作;另一方面,操作系统为每个应用配置地址翻译规则,但不参与具体的翻译过程。
具体来说,CPU中的重要部件—— 内存管理单元(Memory Management Unit, MMU) 负责虚拟地址到物理地址的转换。即,应用在CPU上运行时,它使用的虚拟地址由MMU转化为物理地址。当需要访问内存时,MMU翻译得到的物理地址通过总线传到物理内存,从而完成物理内存的读写。
地址翻译体现了”策略与机制分离“的设计思路:操作系统仅仅负责配置地址翻译规则(策略),地址翻译则由CPU完成(机制),二者通过一个特定的数据结构(页表,功能是记录地址翻译规则)实现协同。我们将在下一节介绍页表。
分页机制和页表
分页机制的基本思想是把应用的虚拟地址空间划分为连续、等长的虚拟页,同时物理地址空间也被划分为连续、等长的物理页。
假设页大小为4KB,那么虚拟地址0x 0000~0x 1000(即0B~4KB)是虚拟页0,0x 1000~0x 2000(即4KB~8KB)是虚拟页1;类似地,物理地址0x 0000~ 0x1000是物理页0,0x 1000~0x 20000是物理页1。
内存地址一般用十六进制数表示,0x 1000中前面的“0x”表示这是一个十六进制数字,对应的十进制数是4096,即4K。但是计算机读入的数都是二进制数。
虚拟页和物理页大小固定且相等,因此操作系统可以轻松为应用构建一张记录虚拟页到物理页的映射关系表,即页表。
有了分页机制后,虚拟/物理地址就可以看作由两部分组成:第一部分标识对应的 页号 ,第二部分标识 页内偏移 。假如页大小为4KB,即,则页内偏移需要12位来表示。例如,虚拟地址0x 2008,标识了虚拟页号2和页内偏移0x 8。
这里出现的“用12位来表示”指的是二进制数的前12位,后文中出现的“位数”也指二进制数的位数,例如0x 2008的二进制数为b 0010 0000 0000 1000,这个数字的后12位(0000 0000 1000)表示页内偏移,对应十六进制的后三位。
寻址示意图如下:

MMU拿到应用的虚拟地址(0x 2008)后,查询该应用的页表,得知物理页号是3,得出物理页的基地址为0x 3000,最后加上基地址0x 8得到物理地址0x 3008。
小思考:根据上面的页表,虚拟地址0x1fca对应的物理地址是什么?
这样,对应用来说,自己的地址空间就是连续的:应用只需要使用虚拟地址,不需要关心虚拟地址到物理地址的转换过程。而操作系统可以通过为不同应用建立不同的页表,如对应用A而言,虚拟页号0对应物理页号1,而对应用B而言,虚拟页号0对应物理页号4,从而实现不同应用的内存隔离。
最后,为了使MMU可以在内存中找到页表,需要把页表的起始地址放在特殊的寄存器中,这个寄存器就是页表基地址寄存器,在AArch64平台中,这个寄存器是TTBR(Translation Table Base Register)。
小思考:TTBR中保存的“页表基地址”是物理地址,还是虚拟地址?
多级页表
上文中出现的页表为单级页表,大家可以计算一下,假如虚拟地址一共有48位,页大小为4K,那么一共有个虚拟页。假如每个页表项大小为8 Byte,则页表大小为!而且,这张页表占据的物理内存必须连续!
所以,必须想办法压缩页表的大小。
与此同时,我们发现,大多数应用使用的虚拟地址远远小于总的虚拟地址空间,也即单级页表中的大部分表项根本没有被使用。
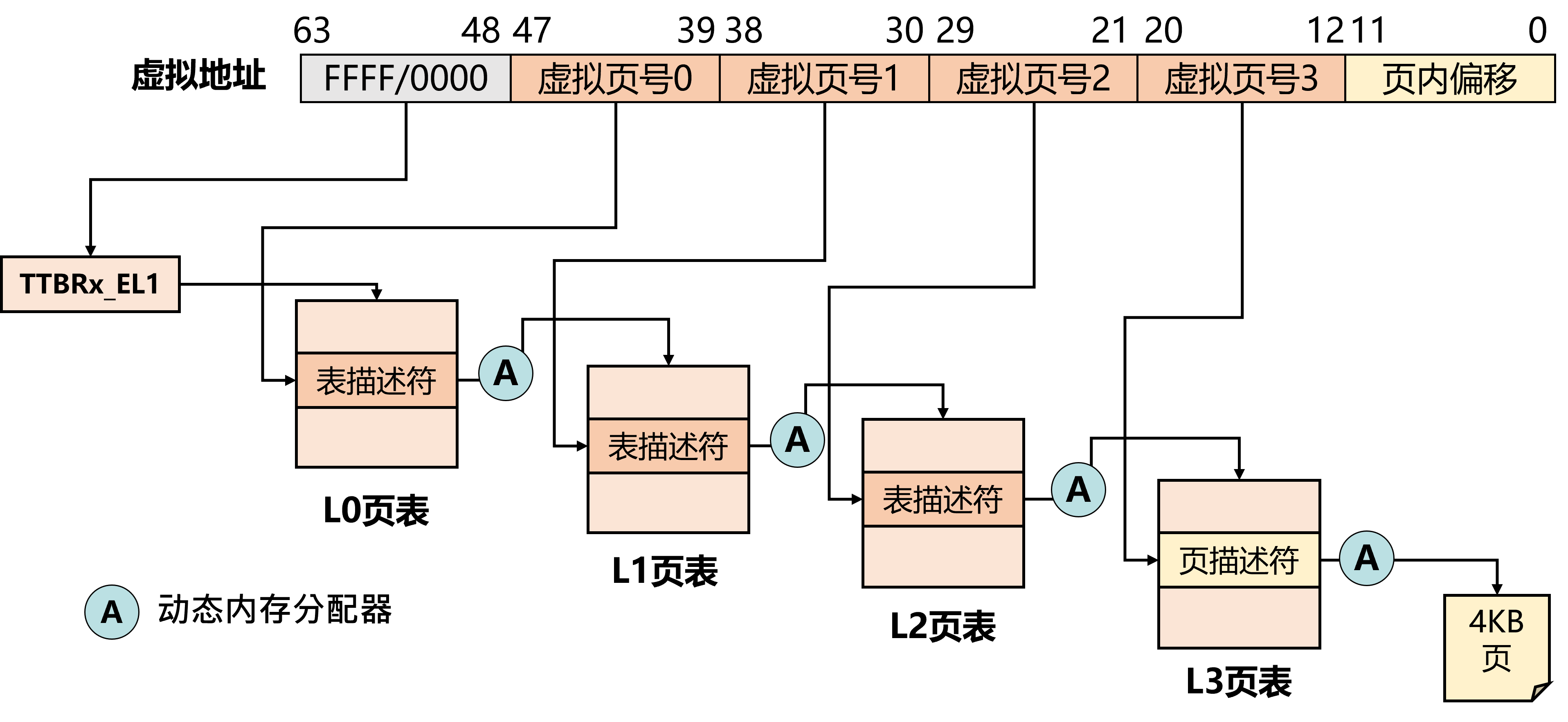
因此,在实际场景中,操作系统通常使用多级页表,如下图:

64位的虚拟地址实际使用于寻址的有48位,其中12到47位标识虚拟页号,0到11位标识页内偏移。虚拟页号被分为四级,每个级有9位。例如,MMU先读入虚拟地址0x 0000 0000 2008,通过TTBR读入L0页表的物理地址后,再根据39到47位获得L0页表的页表项0,然后读取L0页表中存储的L1物理页号,依次读到L3页表,获得其中存储的物理页号,最后根据页内偏移获得数据的物理地址。
因为页大小为4KB,且每个页表项大小为8 Byte,所以每个页表有项,为了索引512个页表项,需要9位,所以虚拟页号的每一级有9位。
多级页表的好处就是,当任意一级页表中的某一个条目位空时,该条目对应的下一级页表不需要存在。换句话说,多级页表允许整个页表结构出现“空洞”,而单级页表则需要每一项都实际存在。
而在实际情况下,应用的虚拟地址空间中绝大多数虚拟地址不会被使用,所以多级页表通常具有许多“空洞”,从而能极大节约页表占用的空间。
思考题 1
1995年,Intel在奔腾Pro处理器上推出PAE(Physical Address Extension)技术,支持36位物理地址(即最大64GB),但虚拟地址依然只有32位(即虚拟地址空间为32GB)。由于物理地址是36位,所以页表项大小为 64位(8 Byte),每个页表依然有512项,使用9位索引,因此使用2+9+9+12三级索引。请计算在用满4GB的虚拟地址空间的情况下,多级页表和单级页表分别占用多少空间?并且思考多级页表一定能减少单级页表占用的空间吗?
AArch64地址翻译
MMU硬件在EL1特权级(操作系统运行的特权级)中提供了两个页表基地址寄存器,分别是TTBR0_EL1和TTBR1_EL1。当虚拟地址的48~63位全为0时,MMU硬件基于TTBR0_EL1寄存器存储的页表进行地址翻译;当虚拟地址的48~63位全为1时,MMU硬件基于TTBR1_EL1寄存器存储的页表进行地址翻译。
即0x 0000 0000 0000 ~ 0x 0000 ffff ffff的地址使用TTBR0_EL1寄存器,0x ffff 0000 0000~0x ffff ffff ffff 的地址使用TTBR1_EL1寄存器。
Hint: ChCore中0x ffff ff00 0000 0000之后的为内核的高地址,不过这不影响我们理解
页表项
页表项(Page Table Entry,简称PTE)一般存储表描述符或页描述符,除了下一级页表(或者物理页)的物理页号(Page Frame Number,简称PFN)外,还存储一些属性位。如下图,第0位为is_valid位,为1时表示这个页表项有效,第1位为is_page或者is_table位,为1时表示页表项中的PFN指向的是页表或者物理页。
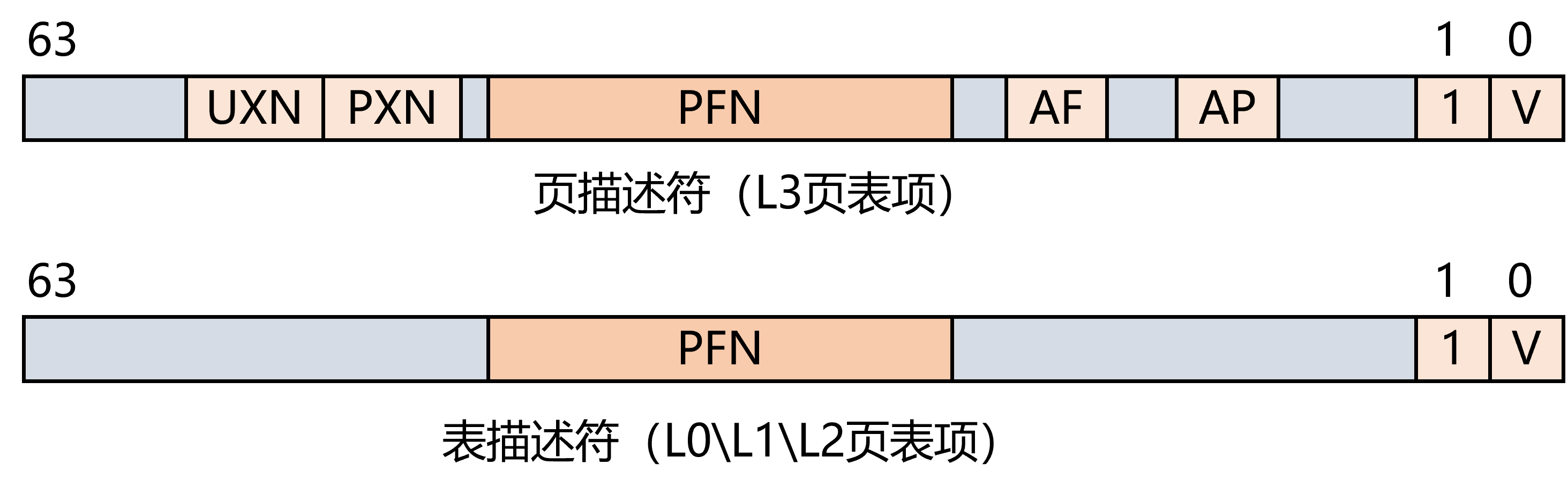
在ChCore中,页表项的定义在文件kernel\include\arch\aarch64\arch\mm\page_table.h 内,
1 | //定义了一些宏 |
思考题 2
上图中还出现了其他属性位,如UXN、PXN、AF、AP,请你阅读ChCore中
kernel\include\arch\aarch64\arch\mm\page_table.h中对pte_t的定义,并结合查阅到的其他资料,说明这四个属性位的作用。
PART 1:配置内核启动页表
在LAB 1中,我们学到内核启动时,开启MMU之前,CPU访问内存使用物理地址,开启MMU之后使用虚拟地址。而在LAB 1的TODO 2里,我们在未配置启动页表时直接启动MMU,因此在这之后,CPU认为自己访问的是虚拟地址,会先查询页表,由于页表未配置,查表失败,因此发生地址翻译错误,执行流来到0x200处无限循环。
具体表现为,在QEMU窗口中只输出两行:

而在gdb调试窗口中,刚好卡在开启MMU之后:
ChCore使用位于kernel\arch\aarch64\boot\raspi3\init\mmu.c中的init_boot_pt函数初始化内核启动页表。在LAB 2中,我们已经配置好了低地址空间的映射表,因此在LAB 2的一开始,QEMU窗口会输出四行,

而通过gdb查询到,我们在init_c函数结束后要跳转到start_kernel函数,而这个函数的虚拟地址是高地址,因此无法顺利跳转:
因此,在LAB 2里,我们的主线任务就是配置内核启动页表🙌
所谓的”配置页表“其实是一个很直接的事情,从上一节我们知道,一个”页表(ptp_t)“就是由页表项(pte_t)数组组成的,所以我们配置的时候就根据虚拟地址找到页表项,然后按照需要填写属性即可。
主要填写的属性有三个:
| is_valid | 1表示有效;0表示无效 |
|---|---|
| is_table or is_page | 1表示有下一级页表或者物理页;0表示没有下一级页表 |
| pfn or next_table_addr | 表示下一级页表或者物理页的物理地址 |
在低地址空间,内核页表的虚拟地址与物理地址一一对应,即虚拟地址A映射到物理地址A。
在高地址空间,内核页表的虚拟地址0x ffff ff00 0000 0000 +A映射到物理地址A。
小思考:为什么建立内核启动页表时既要建立低地址空间的映射,又要建立高地址空间的映射?
所以,我们现在只需要知道地址空间范围,就可以开始配置内核启动页表了,如下表:
| 虚拟地址(高) | 虚拟地址(低) | 物理地址 | 对应设备 |
|---|---|---|---|
| 0xffff ff00 0000 0000 ~ 0xffff ff00 3f00 0000 | 0x 0000 0000 0000 0000 ~ 0x 0000 0000 3f00 0000 | 0x 0000 0000 0000 0000 ~ 0x 0000 0000 3f00 0000 | 物理内存(SDRAM) 类型:NORMAL_MEMORY |
| 0xffff ff00 3f000 0000 ~ 0xffff ff00 4000 0000 | 0x 0000 0000 3f00 0000 ~ 0x 0000 0000 4000 0000 | 0x 0000 0000 3f00 0000 ~ 0x 0000 0000 4000 0000 | 共享外设内存 类型: DEVICE_MEMORY |
| 0xffff ff00 4000 0000 ~ 0xffff ff00 8000 0000 | - | 0x 0000 0000 4000 0000 ~ 0x 0000 0000 8000 0000 | 本地外设内存 类型: DEVICE_MEMORY |
在ChCore的文件kernel/arch/aarch64/boot/raspi3/init/mmu.c中,我们已经以全局变量的方式定义了L0、L1、L2级页表各一个:
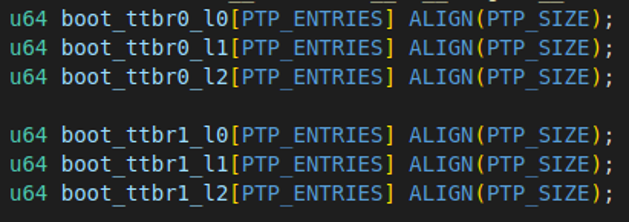
小思考:为什么不定义L3页表?
练习 1
请你在
init_boot_pt函数的LAB 2 TODO 1中补全代码,仿照我们实现的内核低地址映射,完成内核高地址映射。提示:
- 内核代码的高地址空间开始位置存储在宏
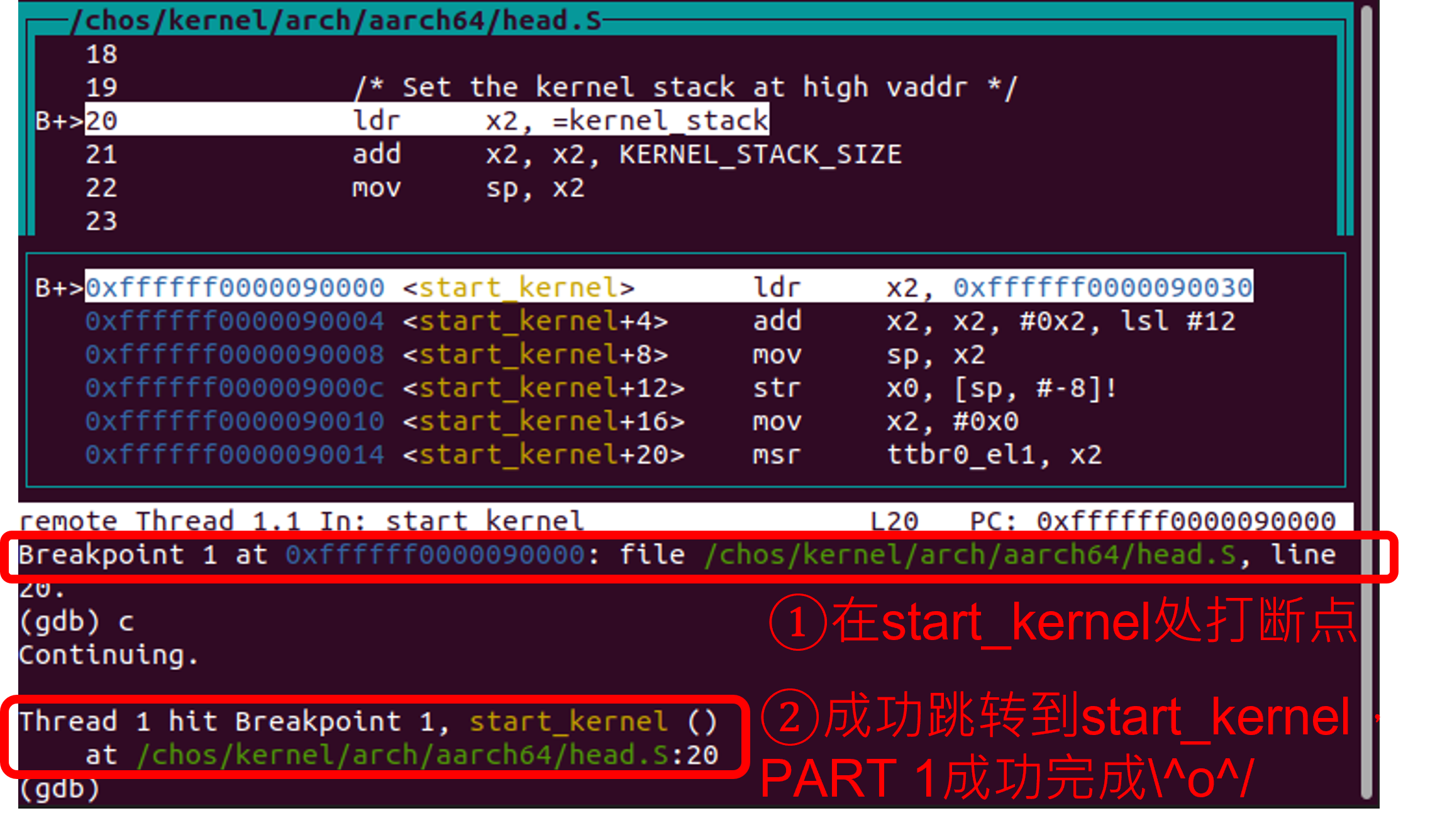
KERNEL_VADDR中。- 练习完成后,可以在start_kernel函数处打断点,测试能否成功通过高地址访问内存。
PART 2:物理内存管理
上一部分我们成功配好了内核启动页表,此时ChCore可以顺利跳转到start_kernel,随后跳转到main函数,完成内核启动(boot)ヽ(✿゚▽゚)ノ
但是,为了快速启动内核,我们使用的所有页表页的地址都是静态分配的!
在理论课的学习中,我们想象中的页表配置应该是动态分配的:
因此,PART 2里我们将实现一个动态内存分配器。
作为OS领域经久不衰的研究课题,动态内存分配器干的最重要的三件事是:管理所有空闲页、分配空闲页和释放已分配的空闲页。
ChCore里使用struct page管理物理页,使用struct phys_mem_pool管理一组物理页。其中,在struct phys_mem_pool中定义了空闲链表:
1 | // kernel/include/mm/buddy.h |
接下来,我们在需要空闲页时从空闲链表中剔除页,而在释放空闲页时把释放出的页添加到空闲链表。
具体来说,ChCore使用伙伴系统管理动态内存:
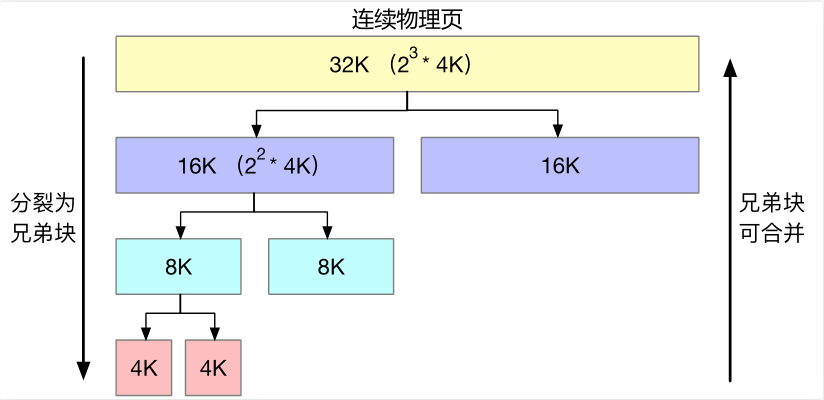
开始时所有页组成一个连续的空间,当有内存分配请求时,这个空间会一份为二,这个分割出来的两份就是”伙伴“,其中一个伙伴还是空闲状态,另一个伙伴则继续分裂,直到获得请求需要的物理内存大小。
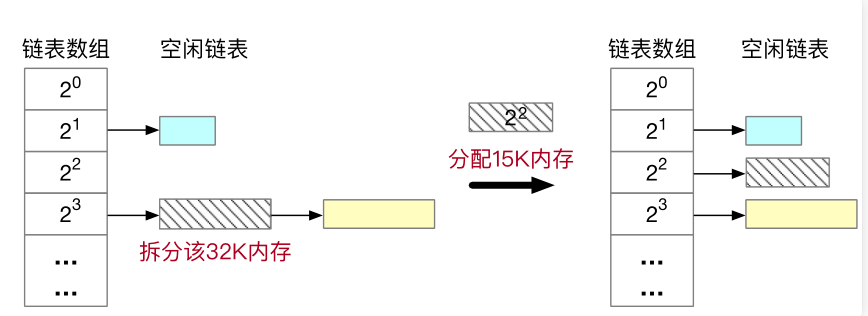
例如,我们需要分配15K的物理内存,我们需要和2的幂次对齐,所以选择向伙伴系统请求16K的空闲内存空间。但目前链表数组中没有16K的空闲空间,因此向上查询更大的空间空间,发现有32K的内存(斜线部分),对其拆分,拆分后得到两16K空闲内存,其中一块插入空闲链表,另一块的物理地址则发送给应用。
练习 2
完成
kernel/mm/buddy.c中的split_page、buddy_get_pages、merge_page和buddy_free_pages函数中的LAB2 TODO2部分。其中,
buddy_get_pages用于分配指定阶大小的连续物理页,buddy_free_pages用于释放已分配的连续物理页。提示:
- 可以使用
kernel/include/common/list.h中提供的链表相关函数如init_list_head、list_add、list_del、list_entry来对伙伴系统中的空闲链表进行操作。- 可使用
get_buddy_chunk函数获得某个物理内存块的伙伴块。- 更多提示见代码注释。
PART 3:页表管理
现在,我们可以使用动态内存分配来配置页表了!
练习 3
完成
kernel/arch/aarch64/mm/page_table.c中的query_in_pgtbl、map_range_in_pgtbl、unmap_range_in_pgtbl函数中的 LAB 2 TODO 3 部分,分别实现页表查询、映射、取消映射操作。提示:
- 实现中可以使用
get_next_ptp、set_pte_flags、GET_LX_INDEX等已经给定的函数和宏。- 更多提示见代码注释。
思考题(选做)
课堂上我们提到内存页大小为4KB,使用了L0、L1、L2、L3四级页表。其实Linux还实现了“大页”,其大小有2MB、1GB等。
请你查阅相关资料,描述2MB和1GB的页表结构以及对应的虚拟地址的各个位的划分,并描述大页相比4KB页的优缺点。
思考题(选做)
请你查阅相关资料,调研slab分配器,并说明它与伙伴系统的不同之处,以及Linux中它们是如何共同管理内存空间的。
思考题(选做)
在ChCore中,我们对内核启动页表初始化时,L0、L1和L2级页表页已经静态地分配好了,所以我们能直接对内核启动页表初始化。
请你查阅资料,结合代码,描述Linux 2.6是如何初始化内核启动页表的?
提示:可以阅读《深入理解Linux内核》第三版第74页到78页的内容,这里描述了Linux 2.6的内核启动页表初始化过程。
挑战题(选做)
使用前面实现的 page_table.c 中的函数,在内核启动后重新配置内核页表,进行细粒度的映射。
小思考的答案
- 0x0fcs
- 物理地址
- 因为内核启动时需要在低地址运行一段时间,随后才跳转到高地址。
- 有三点原因:其一,内核启动时不存在其他应用的干扰,因此可以直接建立一大块内存的映射;其二,为了快速配好内核启动页表,完成启动;其三,此时还没实现动态内存分配器,无法动态分配页表页。需要建立映射的地址空间跨度为2G,需要大量L3页表,而只需要L0、L1和L2页表各一个。