FAST 16 - CFFS阅读笔记
The Composite-file File System: Decoupling the One-to-One Mapping of Files and Metadata for Better Performance
Author: Shuanglong Zhang. et al
Conference or Journal: FAST;TOS
Institute: Google & Florida State University
IsOpenSource: No
Link: https://www.usenix.org/system/files/conference/fast16/fast16-papers-zhang-shuanglong.pdf
Published Date: February 22, 2016 → March 1, 2020
摘要
传统的文件系统优化是基于文件与其元数据一一对应的基础上进行的,而这种文件-元数据的绑定会限制一些优化。本文设计并且实现、评估了一种复合文件文件系统,即允许文件到元数据的多对一映射。同时本文评估了多种映射机制的实现方式。在web服务器和软件生产工作集中,实证分析表明,本文提出的方式相比ext4,有超过27%的性能提升。
背景
文件与元数据的一对一映射会限制一些优化方案。例如,预取多个文件块时也需要预取对应文件的元数据——而这是预取的主要副作用。有研究表明,访问32个小文件的延迟比访问同样大小的大文件的延迟高50%。
因此,作者提出把多文件复合,公用同一个元数据,以减少对元数据的磁盘访问。
动机
具体来说,除了上文提到的预取开销,作者提出CFFS(Composite-File File System)的其他动机如下:
- 频繁的小文件访问
作者内部的分析表明,超过80%的文件访问是针对小于32KB的小文件的。在从磁盘读取小文件花费的时间中,接近40%的时间花在了元数据访问上。所以,减少元数据I/O访问开销很有效。
- 冗余的元数据信息
许多文件的元数据属性是一致的,例如文件持有者、访问权限等。有研究表明,在工作站中对元数据压缩有最多75%的压缩率。使用共用的元数据只能减少很少的空间占用,但可以减少很多对元数据的I/O访问。
- 文件成组访问
研究表明,文件大多数是一起被访问的。例如访问网页时会访问其中引用的文件页。但是,之前针对此的方法的性能提升并不是线性的,因为有文件聚集的开销。
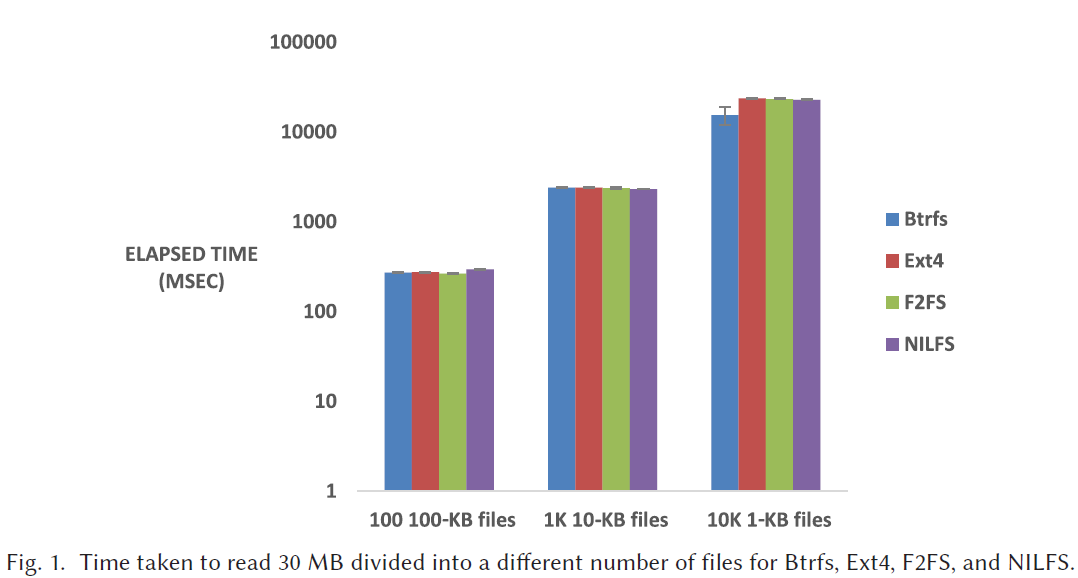
- 访问每个文件的开销比较高
如下图,访问同样大小的数据,访问开销与文件大小成反比。同时印证了背景中提出的小文件开销过大的问题。
复合文件的文件系统(Composite-File File System, CFFS)设计
**复合文件:**多个频繁被一起访问的小文件(子文件)组成复合文件,并共享一个元数据。小文件独有的元数据信息存储在 inode 中的 extented attribute 里。
复合文件对用户不可见,而且针对文件的各种语义(包括日志等)和操作的方式保持不变。
此时可以透明地利用VFS的预取以把多个小文件一起取到内存中。
1、数据的表现形式
子文件中的第一个文件是一个“entry point”,即开启预取的点。
2、元数据的表现形式和对应操作
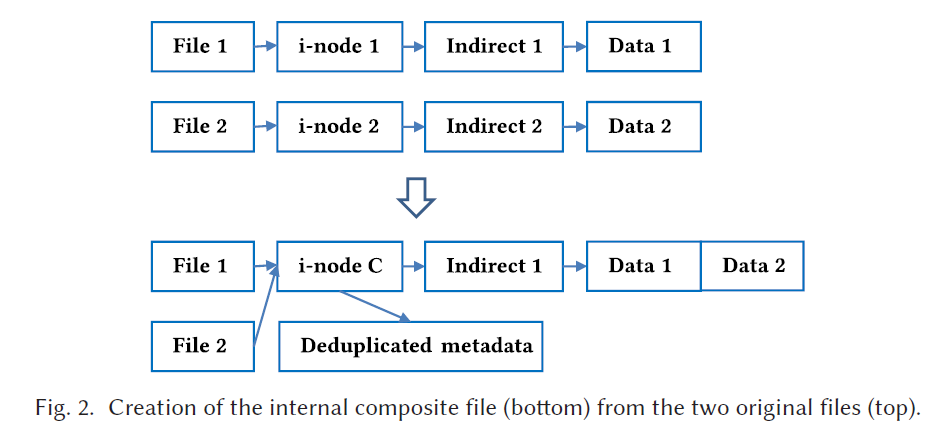
- 复合文件创建
如下图:
- 权限
复合文件的 inode 的权限是所有子文件的权限的并集,每个子文件额外的权限会存储在附加属性中。
- 文件大小
当处于中间的子文件释放时,不会改变复合文件的大小。除非复合文件的空间利用率小于50%。
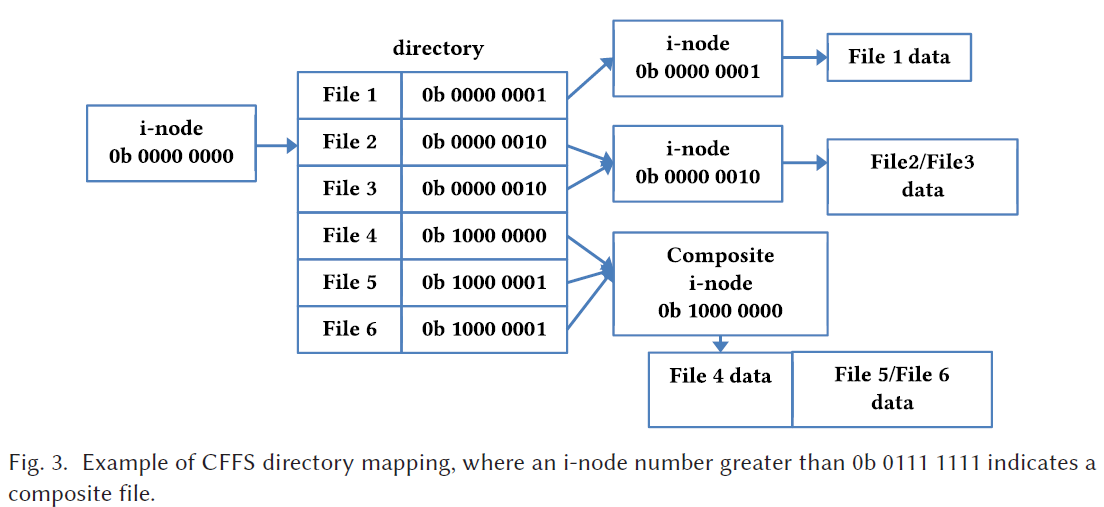
inode命名空间
复合文件的ID的高N位是复合文件的 inode id,低M位用于子文件的ID。整个ID在本文中被称为 CUID 。如下图:
- 重命名
如果不包括把一个普通文件转化为复合文件(或者相反的操作),则重命名不改变 CUID ,反之,重命名会改变 CUID 。
这一设定对根据
inode的“唯一性”、“不变性”来识别文件的应用不友好。
- 锁
复合文件有一个锁,每个子文件同时各有一个锁。通常复合文件的锁可以同时获得,除非会影响到子文件之间的一致性(如更新子文件的成员、移动子文件在复合文件中的位置)。
- 更多
看论文。
3、识别复合文件的成员
- 基于目录的小文件复合
一个目录下的文件常常会被一起访问,所以这种办法把同一个目录下的文件(包括子目录)复合为一个复合文件。这种办法无法捕获目录间的文件关系。
- 基于内部引用的小文件复合
html 文件中常常包含超链接,网络爬虫常常通过这些链接访问其他文件。
此外,基于 Makefile 的规则的编译也暗含了内部引用,即把生成同一个目标的源文件复合。
但问题是这种办法需要对文本格式有了解,进行特定格式的文本分析。
- 基于频率挖掘的小文件复合
可以使用Apriori算法来发掘频繁访问的模式。大致流程如下图:
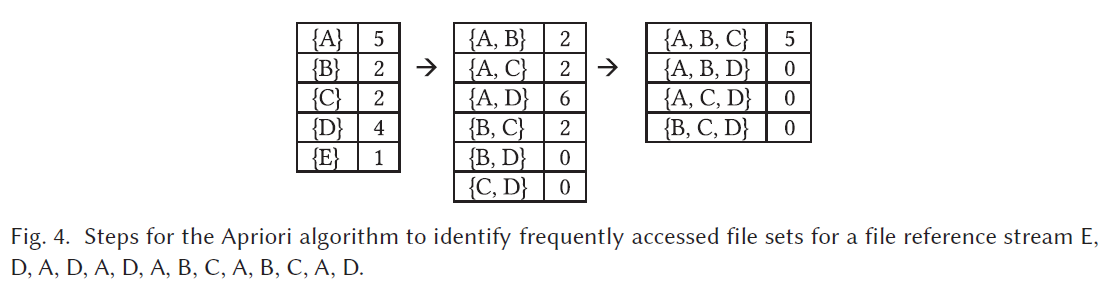
详细原理请参考这里。这种办法的内存和训练开销都很大。
CFFS的实现
本文使用 FUSE(v2.9.3)框架,在用户态建立了CFFS的原型,Linux版本是 3.16.7 ,如下图:
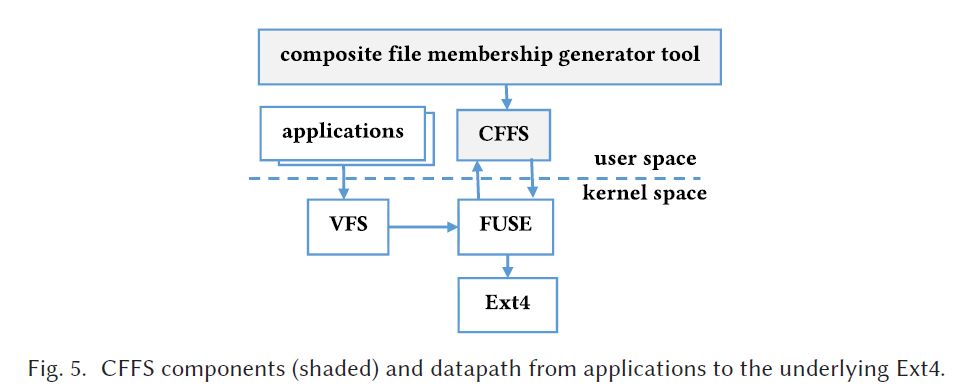
更多内容请见论文。
实验
实验环境

实验结果
Microbenchmark的实验结果
比较:完成时间
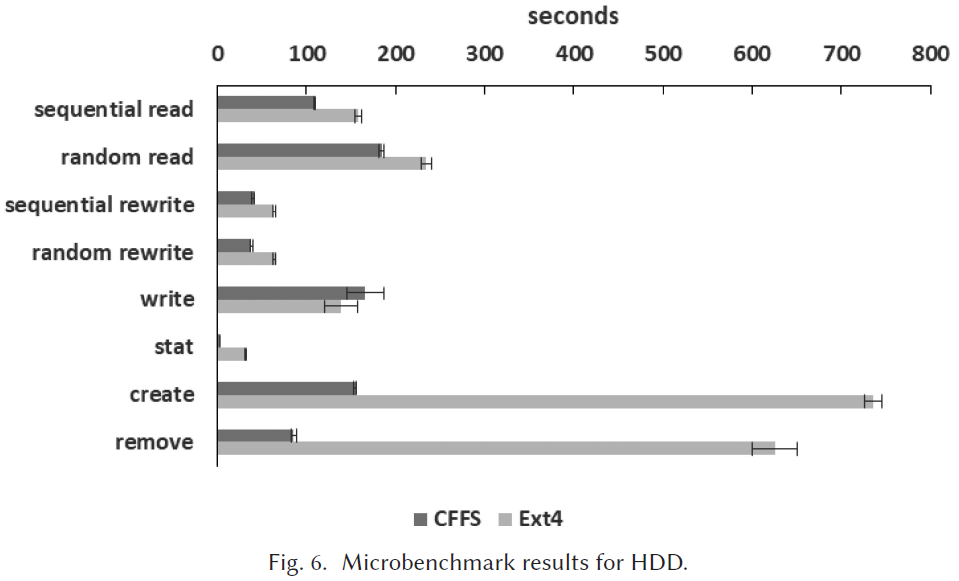
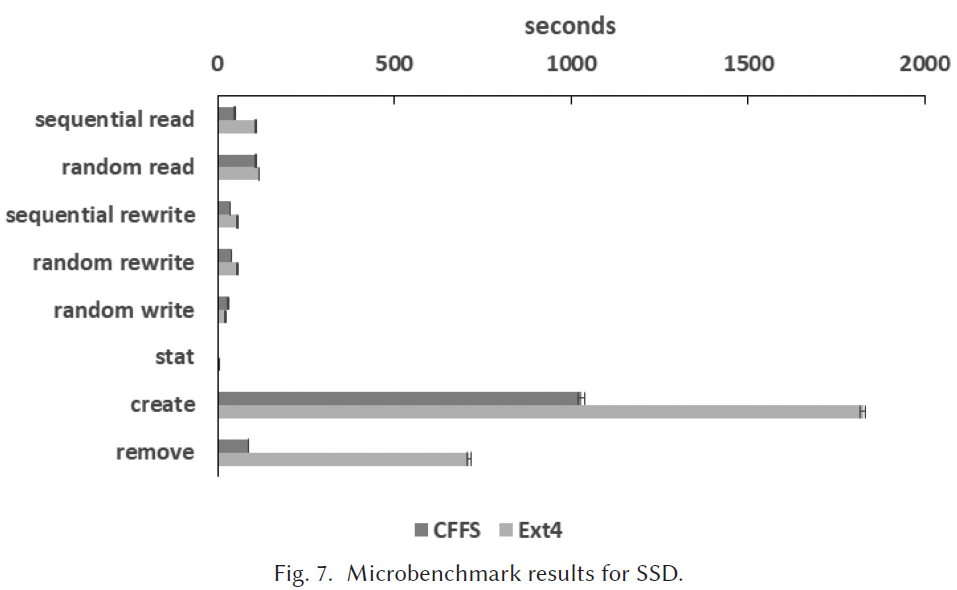
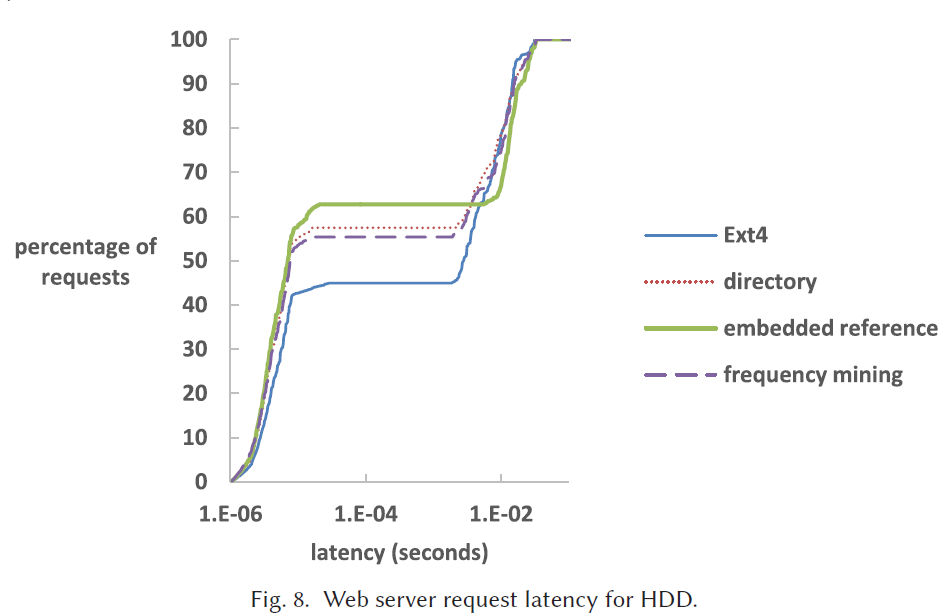
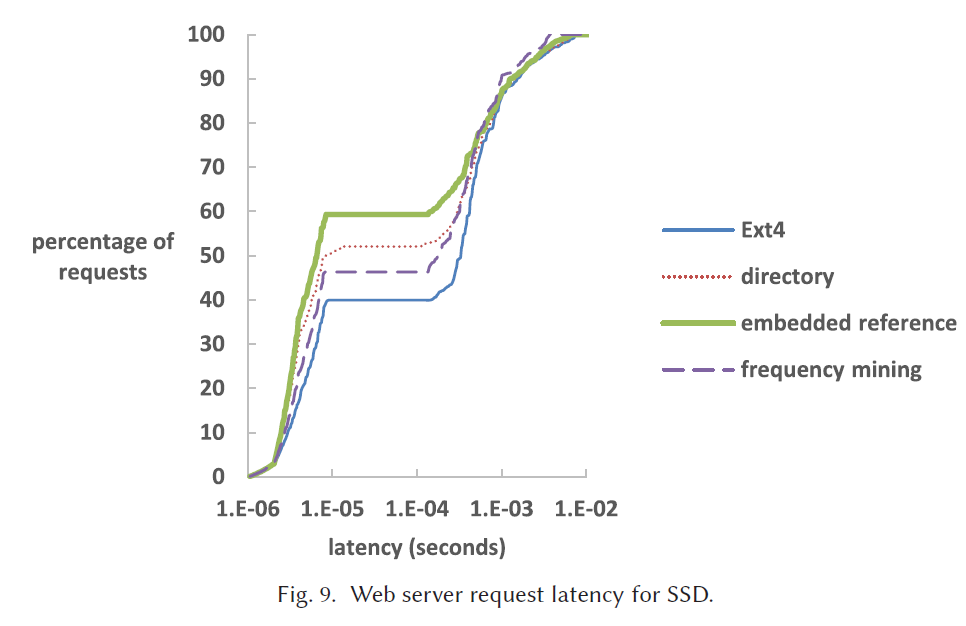
Web Server Trace Replay的实验结果
HDD 中1e-02之前的请求是缓存命中的。
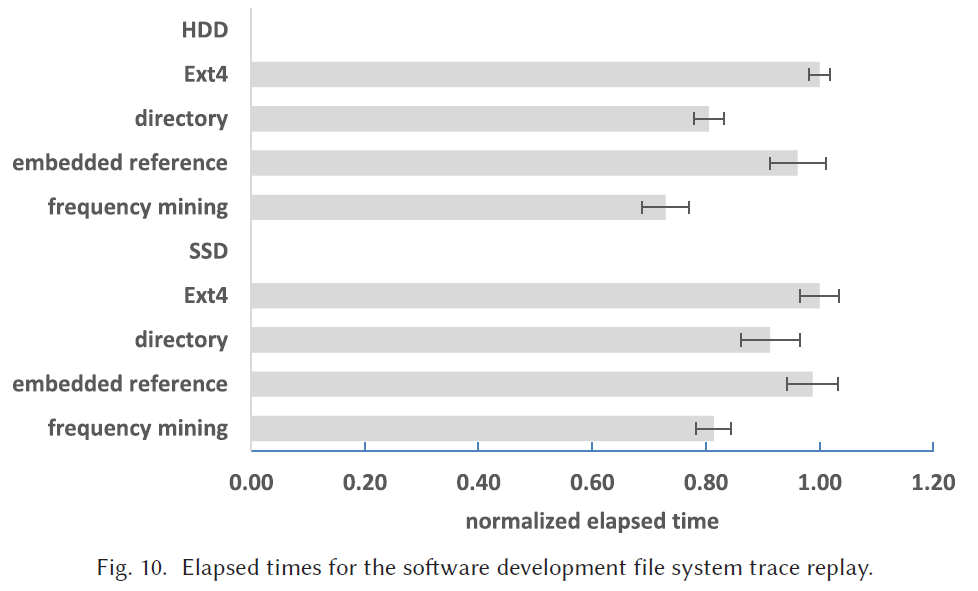
Software Development File System Trace Replay的实验结果
因为不好收集单个请求的延迟,所以这里绘出了整体的完成时间。